Policy-driven, automated compliance enforces zero-trust security principles
Take charge of
access management.
Tools you need. Security you deserve.

Take charge of
access management.
Tools you need. Security you deserve.


Cloud-based SaaS means no software to install and manage on premise

Single source of record for internal and external audits

Step-by-step Onboarding tool with bank-friendly terminology

Implement on your own schedule, add new systems on demand

Flexible reporting capabilities with complete data set—no sampled data

Growing library of Banking and Business Management connectors

Connect to virtually any system, even legacy. Full-APIs not required!

Are You At Risk?
-
Spreadsheets and legacy systems used to track permissions leave security holes for hackers
-
53% of security breaches occur within the institution
-
The cost to remediate averages $8.19M per incident

Provision® IAM Mitigates Security Risks
-
Permissions immediately and automatically update based on your policies
-
Ensures employees have minimal privileges required
-
Automatically eliminates system access for terminated employees
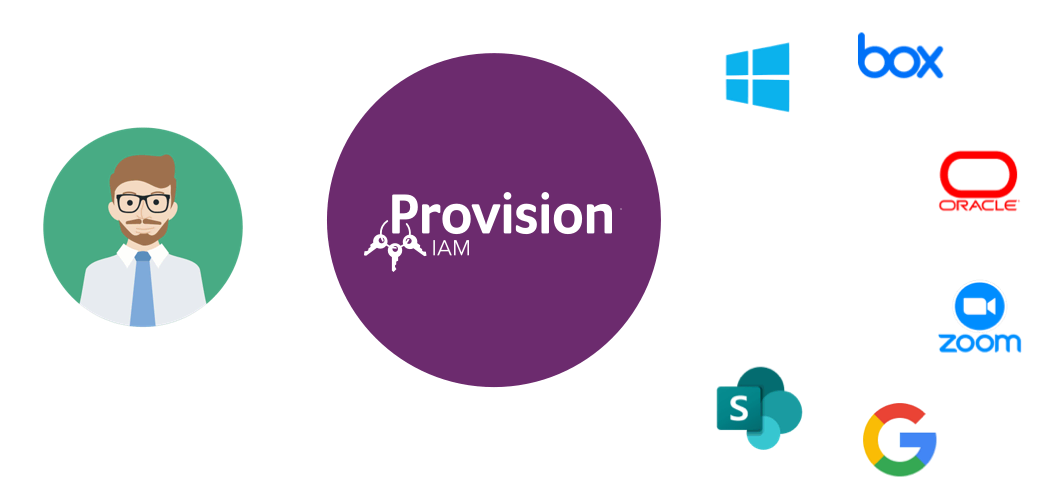
Be Proactive
with Provision® IAM
-
Our self-guided onboarding platform means you can get up and running faster
-
No other IAM platform affordably integrates your systems into an automated, centralized solution
-
Manages users and their unique permissions through built-in workflows
-
Actively documents changes in a well-structured audit log
-
Ensures compliance regulations are being met across all systems

.png?width=750&height=750&name=Untitled%20design%20(32).png)